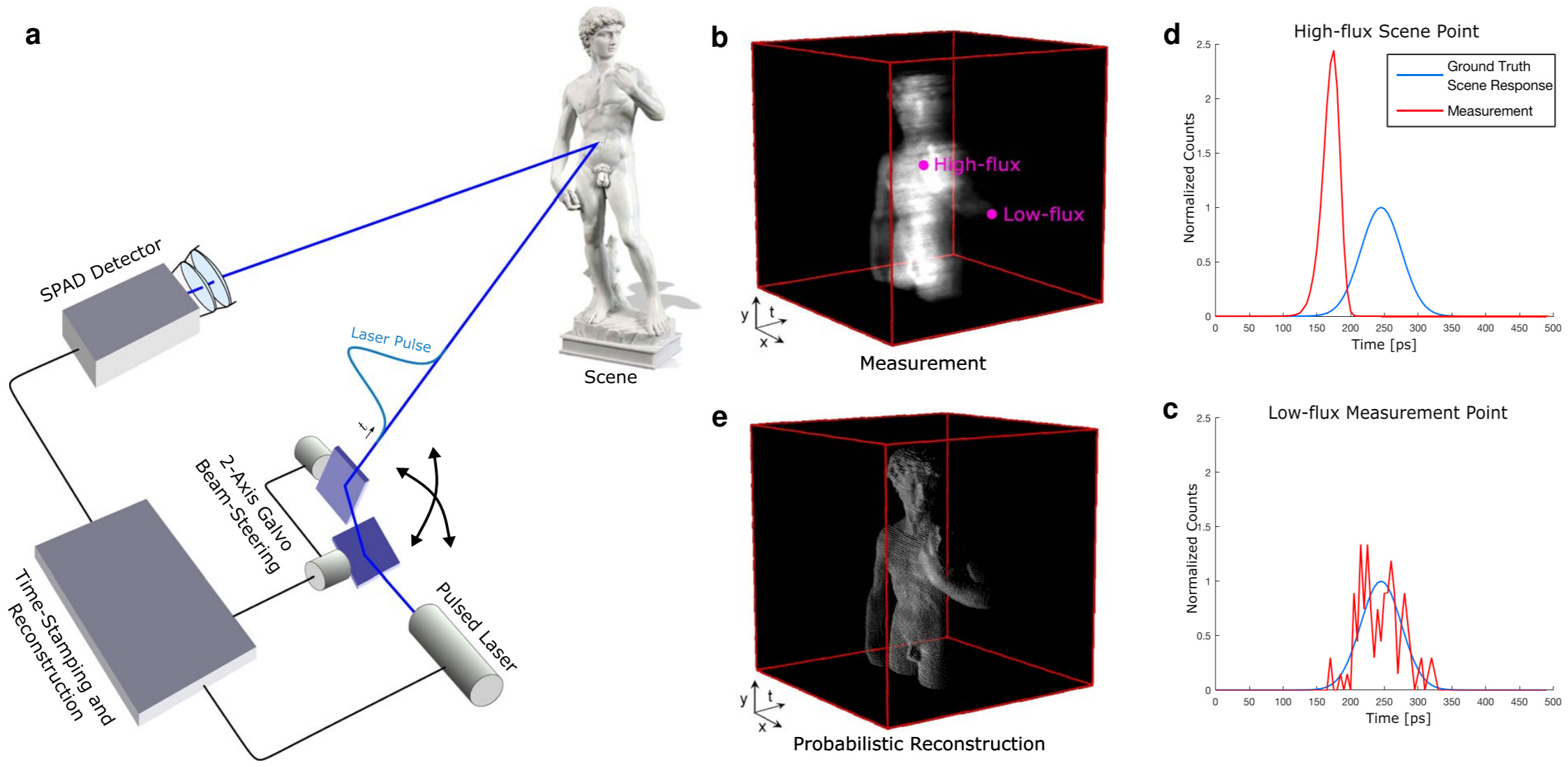
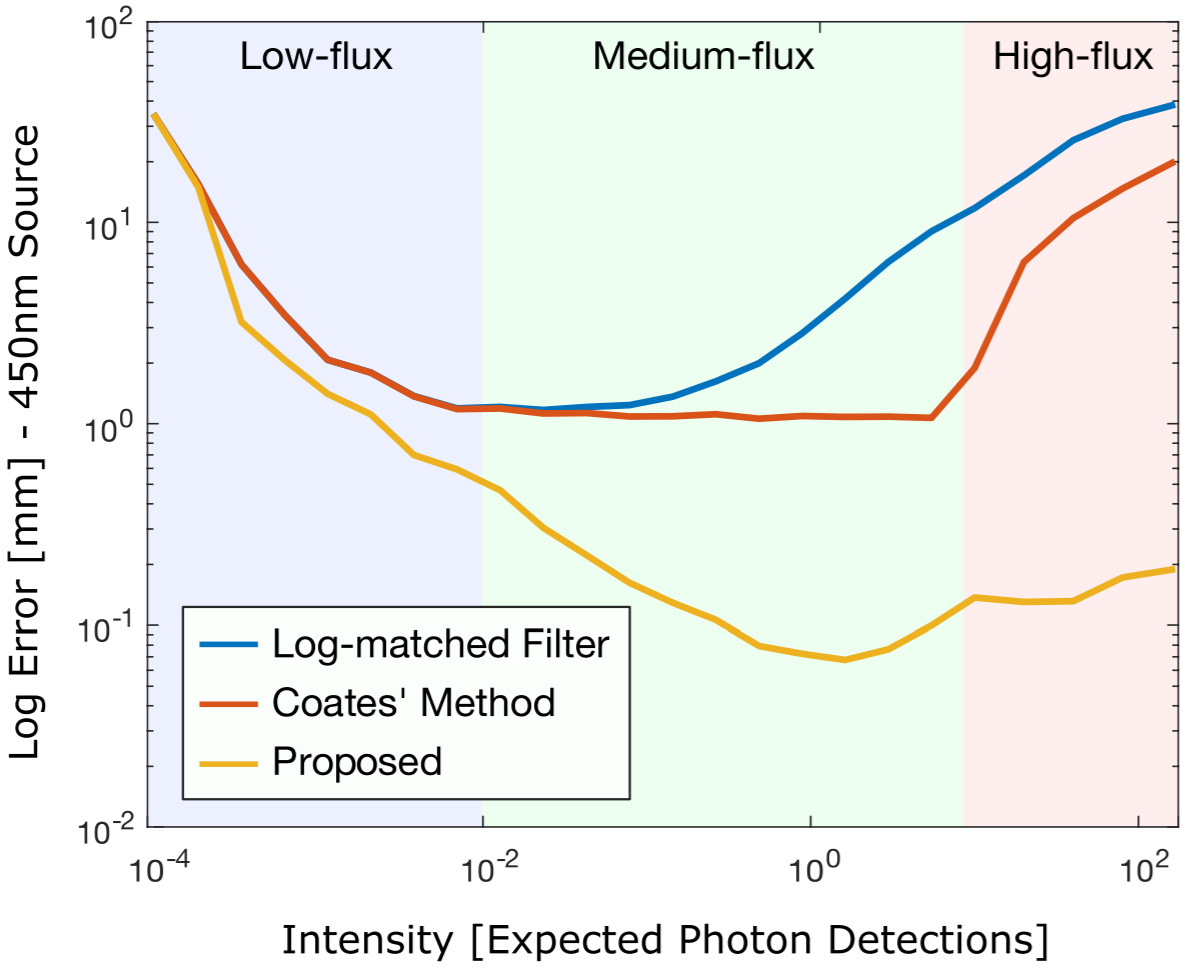
ABSTRACT
Active 3D imaging systems have broad applications across disciplines, including biological imaging, remote sensing and robotics. Applications in these domains require fast acquisition times, high timing accuracy, and high detection sensitivity. Single-photon avalanche diodes (SPADs) have emerged as one of the most promising detector technologies to achieve all of these requirements. However, these detectors are plagued by measurement distortions known as pileup, which fundamentally limit their precision. In this work, we develop a probabilistic image formation model that accurately models pileup. We devise inverse methods to efficiently and robustly estimate scene depth and reflectance from recorded photon counts using the proposed model along with statistical priors. With this algorithm, we not only demonstrate improvements to timing accuracy by more than an order of magnitude compared to the state-of-the-art, but our approach is also the first to facilitate sub-picosecond-accurate, photon-efficient 3D imaging in practical scenarios where widely-varying photon counts are observed.