ABSTRACT
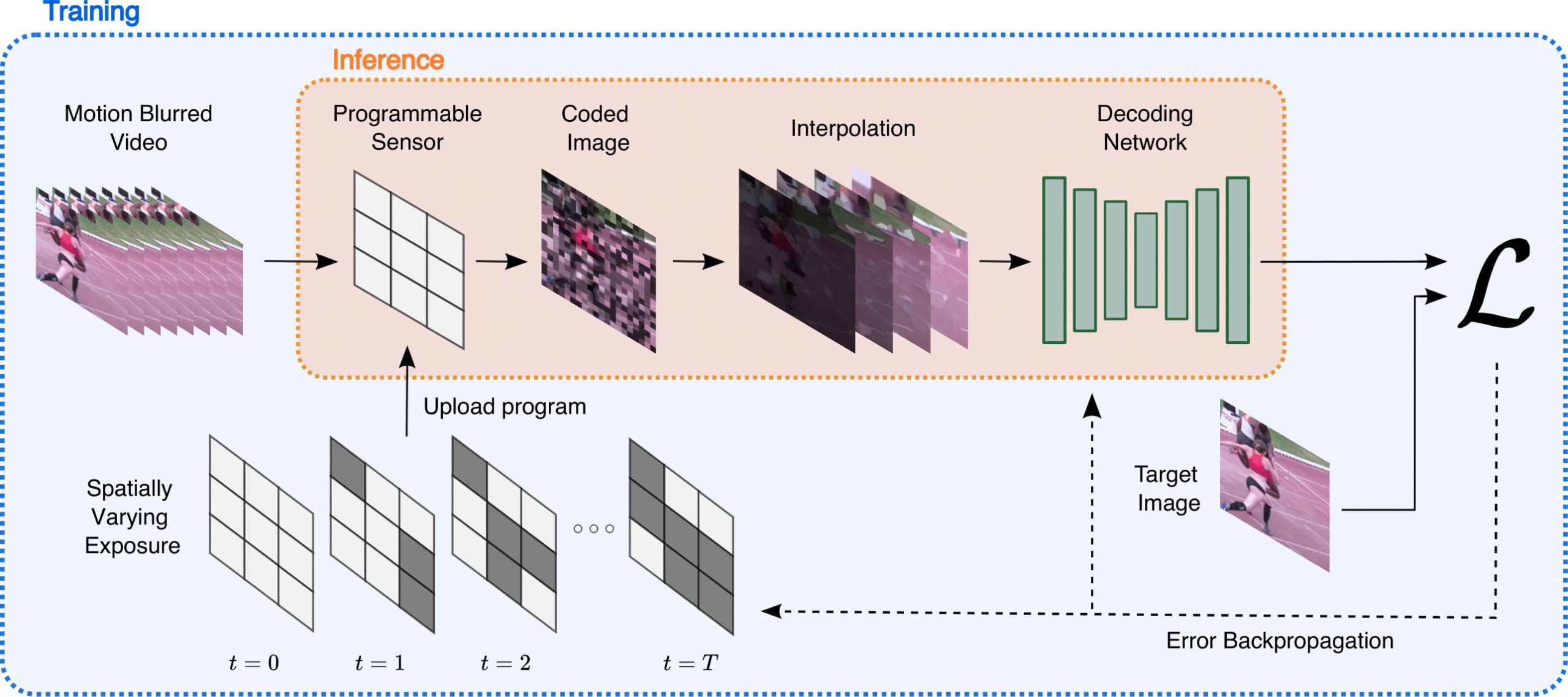
Computationally removing the motion blur introduced by camera shake or object motion in a captured image remains a challenging task in computational photography. Deblurring methods are often limited by the fixed global exposure time of the image capture process. The post-processing algorithm either must deblur a longer exposure that contains relatively little noise or denoise a short exposure that intentionally removes the opportunity for blur at the cost of increased noise. We present a novel approach of leveraging spatially varying pixel exposures for motion deblurring using next-generation focal-plane sensor–processors along with an end-to-end design of these exposures and a machine learning–based motion-deblurring framework. We demonstrate in simulation and a physical prototype that learned spatially varying pixel exposures (L-SVPE) can successfully deblur scenes while recovering high frequency detail. Our work illustrates the promising role that focal-plane sensor–processors can play in the future of computational imaging.