ABSTRACT
We present a diffusion-based model for 3D-aware generative novel view synthesis from as few as a single input image. Our model samples from the distribution of possible renderings consistent with the input and, even in the presence of ambiguity, is capable of rendering diverse and plausible novel views. To achieve this, our method makes use of existing 2D diffusion backbones but, crucially, incorporates geometry priors in the form of a 3D feature volume. This latent feature field captures the distribution over possible scene representations and improves our method’s ability to generate view-consistent novel renderings. In addition to generating novel views, our method has the ability to autoregressively synthesize 3D-consistent sequences. We demonstrate state-of-the-art results on synthetic renderings and room-scale scenes; we also show compelling results for challenging, real-world objects.
FILES
CITATION
E. Chan, K. Nagano, M. Chan, A. Bergman, JJ Park, A. Levy, M. Aittala, S. De Mello, T. Karras, G. Wetzstein, GeNVS: Generative Novel View Synthesis with 3D-Aware Diffusion Models, ICCV 2023
@inproceedings{chan2023genvs,
author = {Eric R. Chan and Koki Nagano and Matthew A. Chan and Alexander W. Bergman and Jeong Joon Park and Axel Levy and Miika Aittala and Shalini De Mello and Tero Karras and Gordon Wetzstein},
title = {{GeNVS}: Generative Novel View Synthesis with {3D}-Aware Diffusion Models},
booktitle = {ICCV},
year = {2023}
}
GeNVS framework
|
|
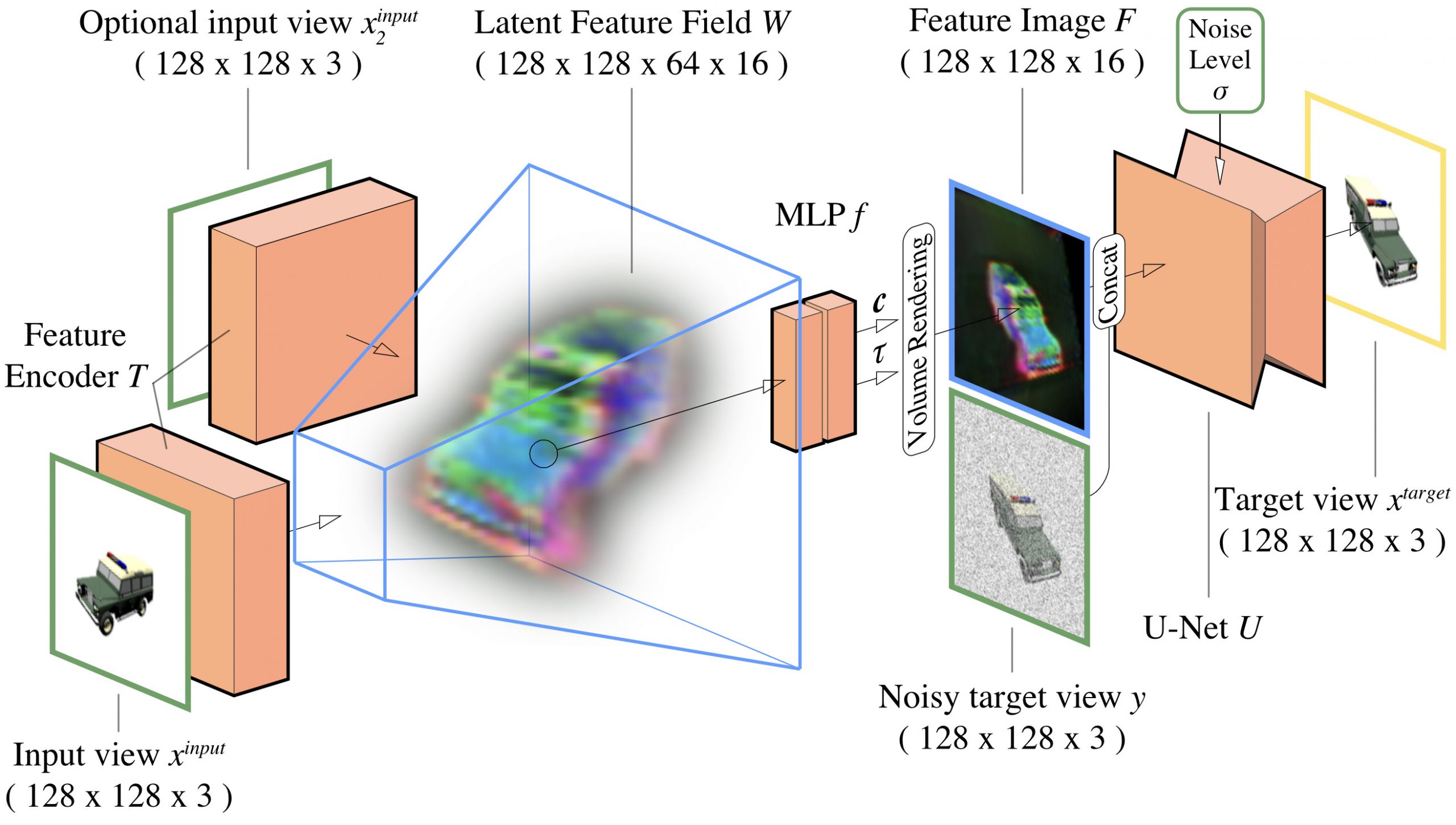
| At a high level, our model operates as a conditional diffusion model for images, much like the models that have been successful in image inpainting, superresolution, and other conditional image generation tasks. Conditioned on an input view, we generate novel views by progressively denoising a sample of Gaussian noise. However, in this work, we embed 3D priors into the architecture in the form of a 3D feature field, which enhances the model’s ability to synthesize views on complex scenes. We lift and aggregate features from input image(s) into a 3D feature field. Given a query viewpoint, we volume-render a feature image to condition a U-Net image denoiser. The entire model, including feature encoder, volume renderer, and U-Net components, is trained end-to-end as an image-conditional diffusion model. At inference, we generate consistent sequences in an auto-regressive fashion. |