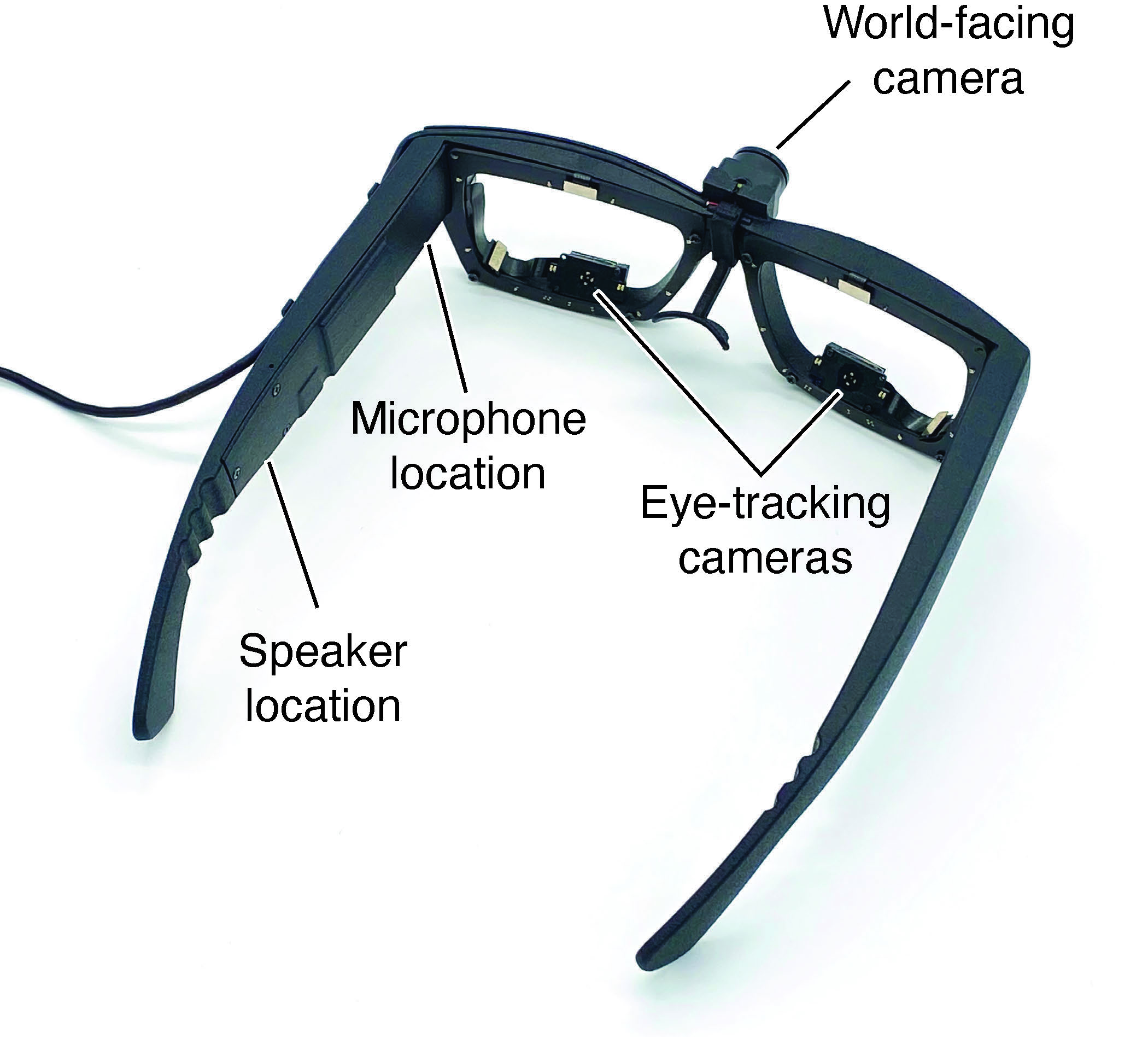
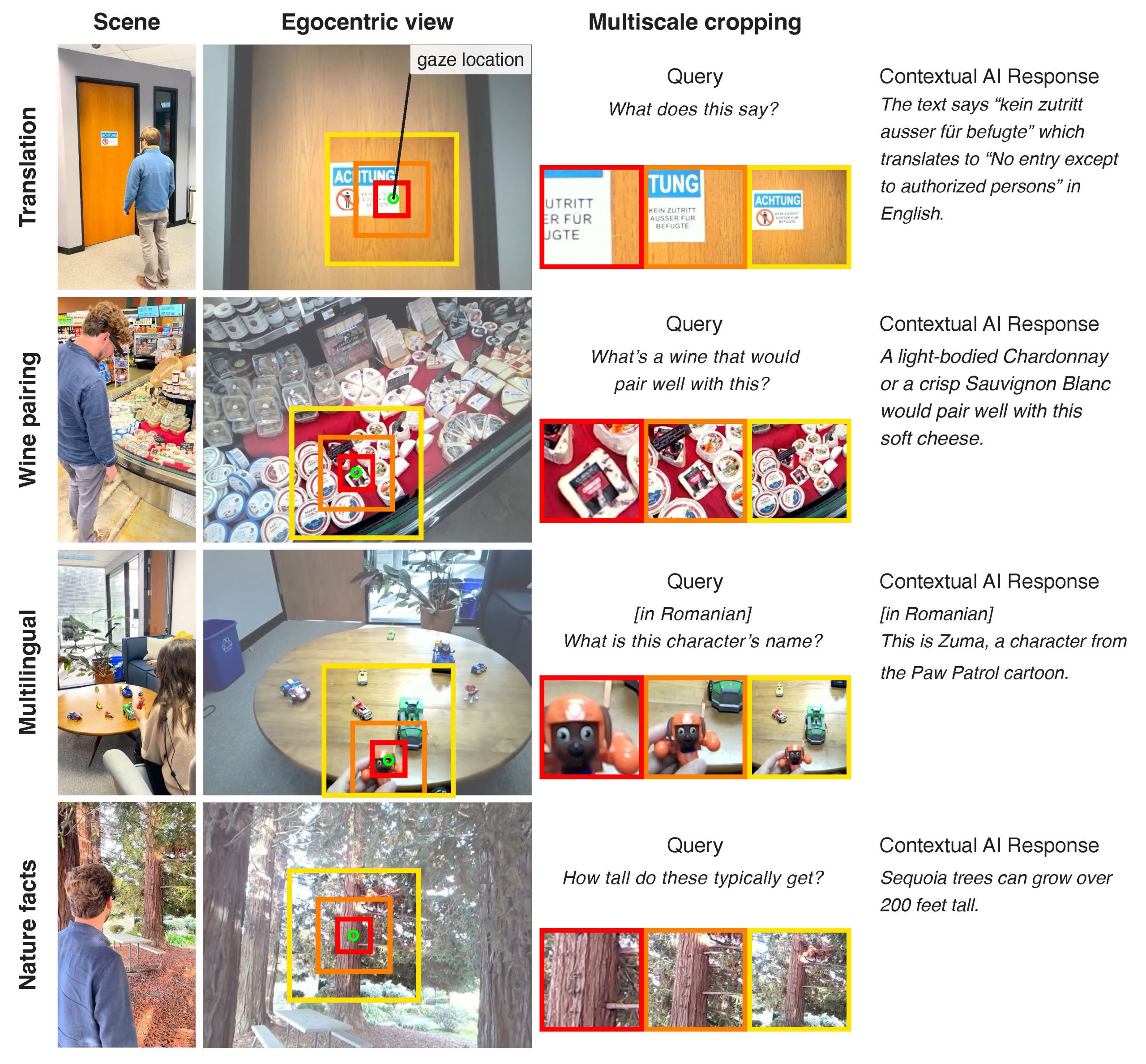
ABSTRACT
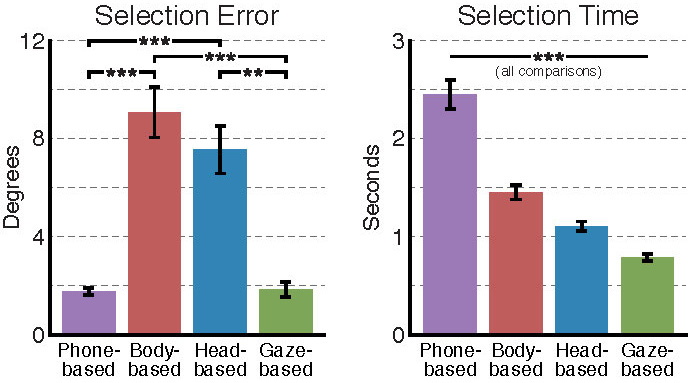
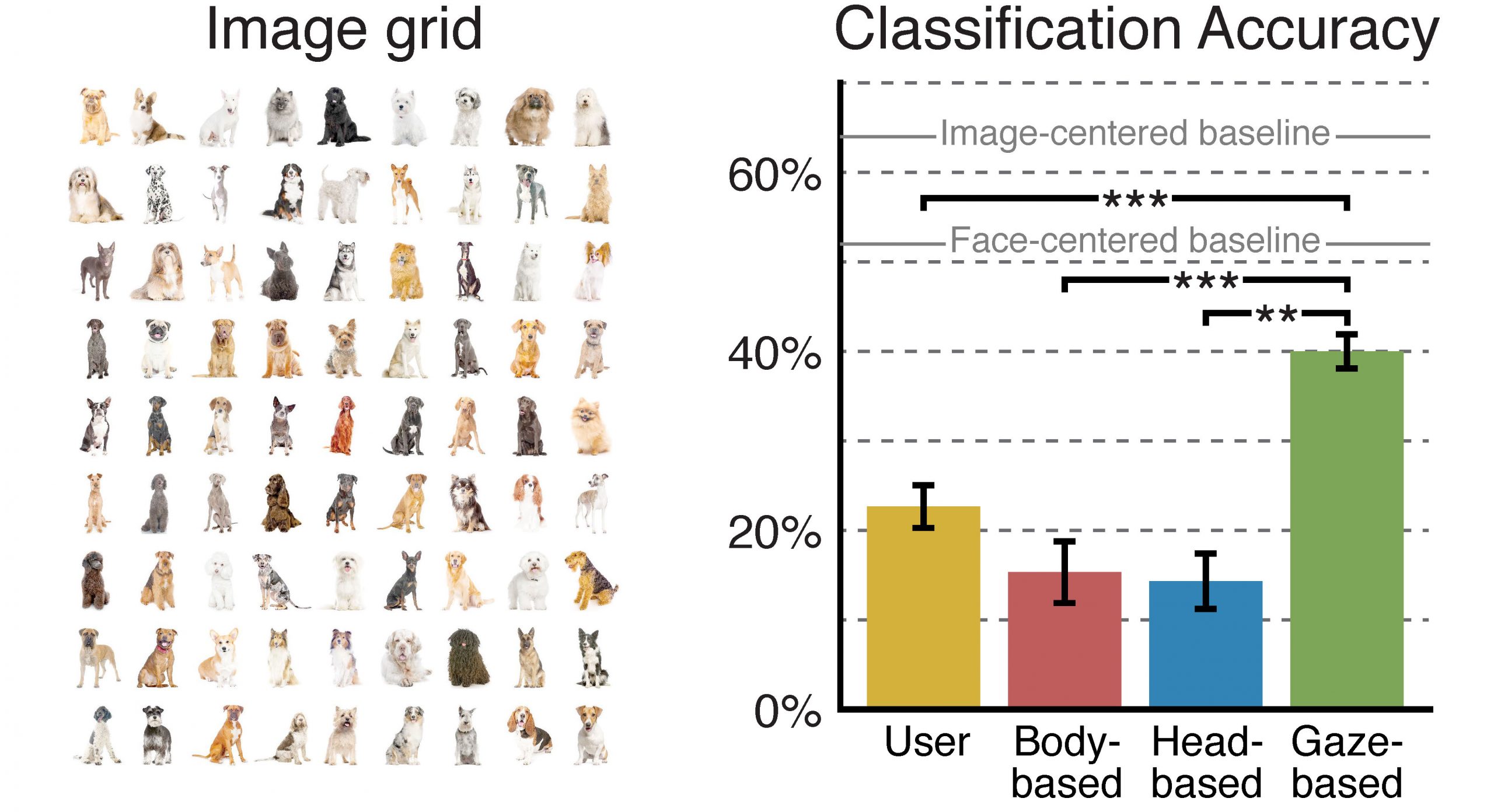
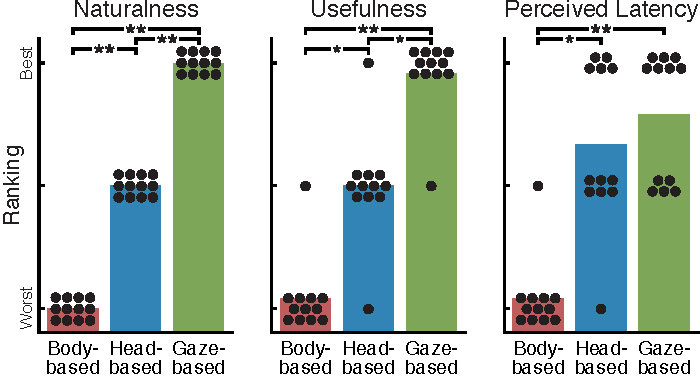
Multimodal large language models (LMMs) excel in world knowledge and problem-solving abilities. Through the use of a world-facing camera and contextual AI, emerging smart accessories aim to provide a seamless interface between humans and LMMs. Yet, these wearable computing systems lack an understanding of the user’s attention. We introduce GazeGPT as a new user interaction paradigm for contextual AI. GazeGPT uses eye tracking to help the LMM understand which object in the world-facing camera view a user is paying attention to. Using extensive user evaluations, we show that this gaze-contingent mechanism is a faster and more accurate pointing mechanism than alternatives; that it augments human capabilities by significantly improving their accuracy in a dog-breed classification task; and that it is consistently ranked as more natural than head- or body-driven selection mechanisms for contextual AI. Moreover, we prototype a variety of application scenarios that suggest GazeGPT could be of significant value to users as part of future AI-driven personal assistants.