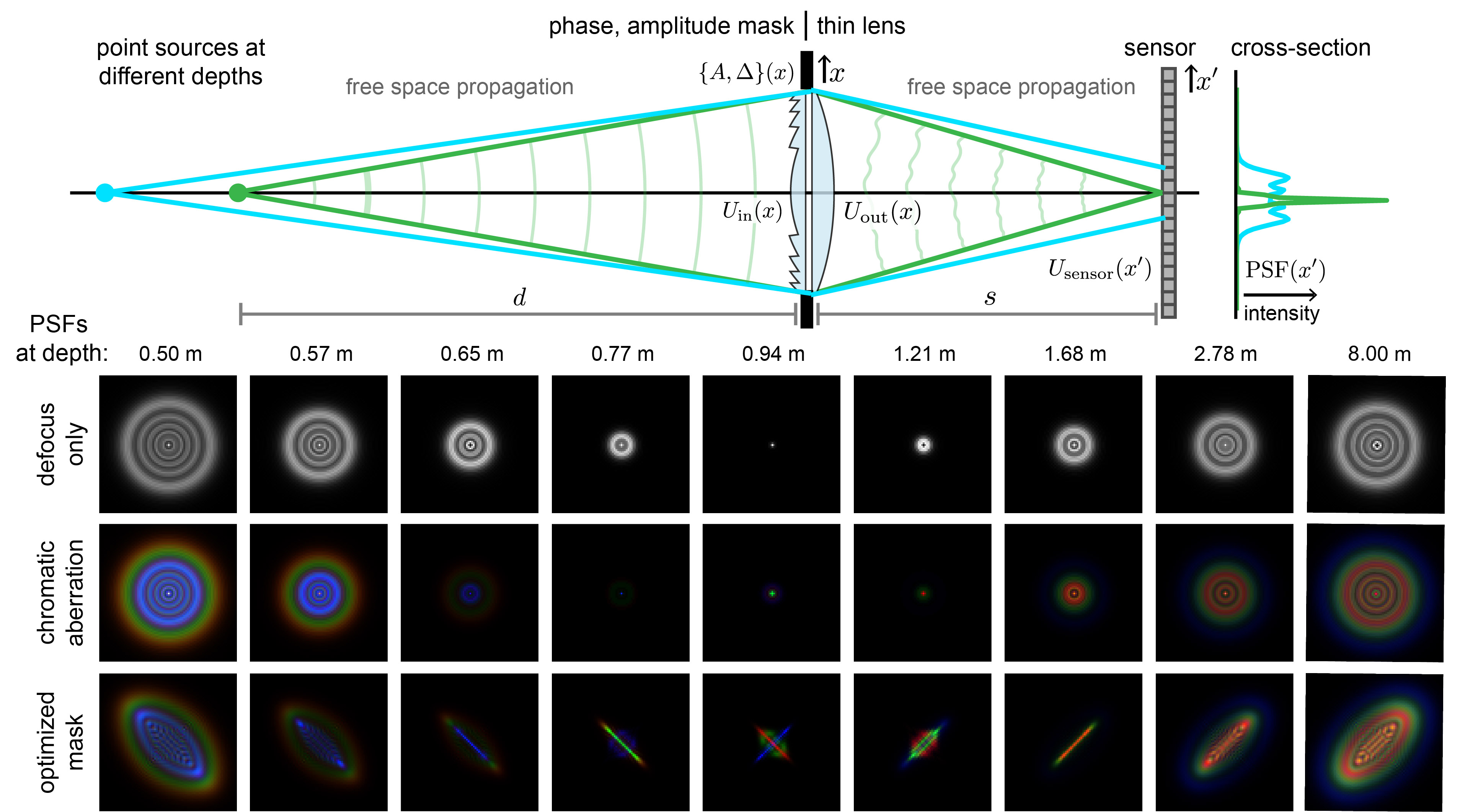
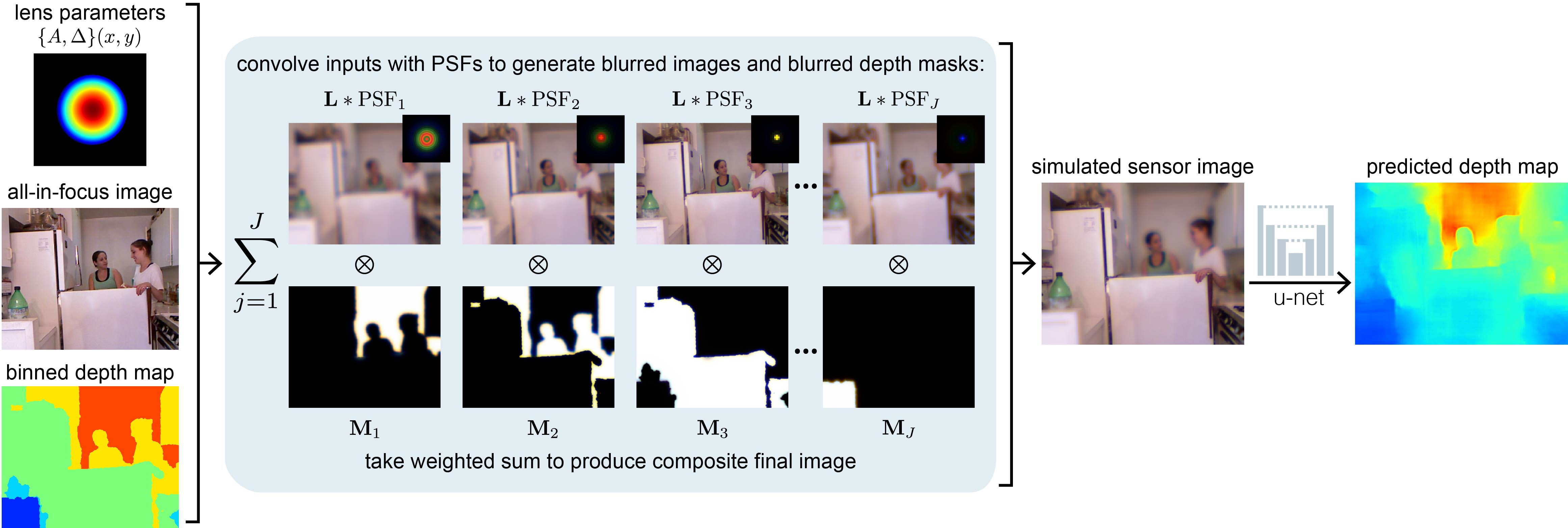
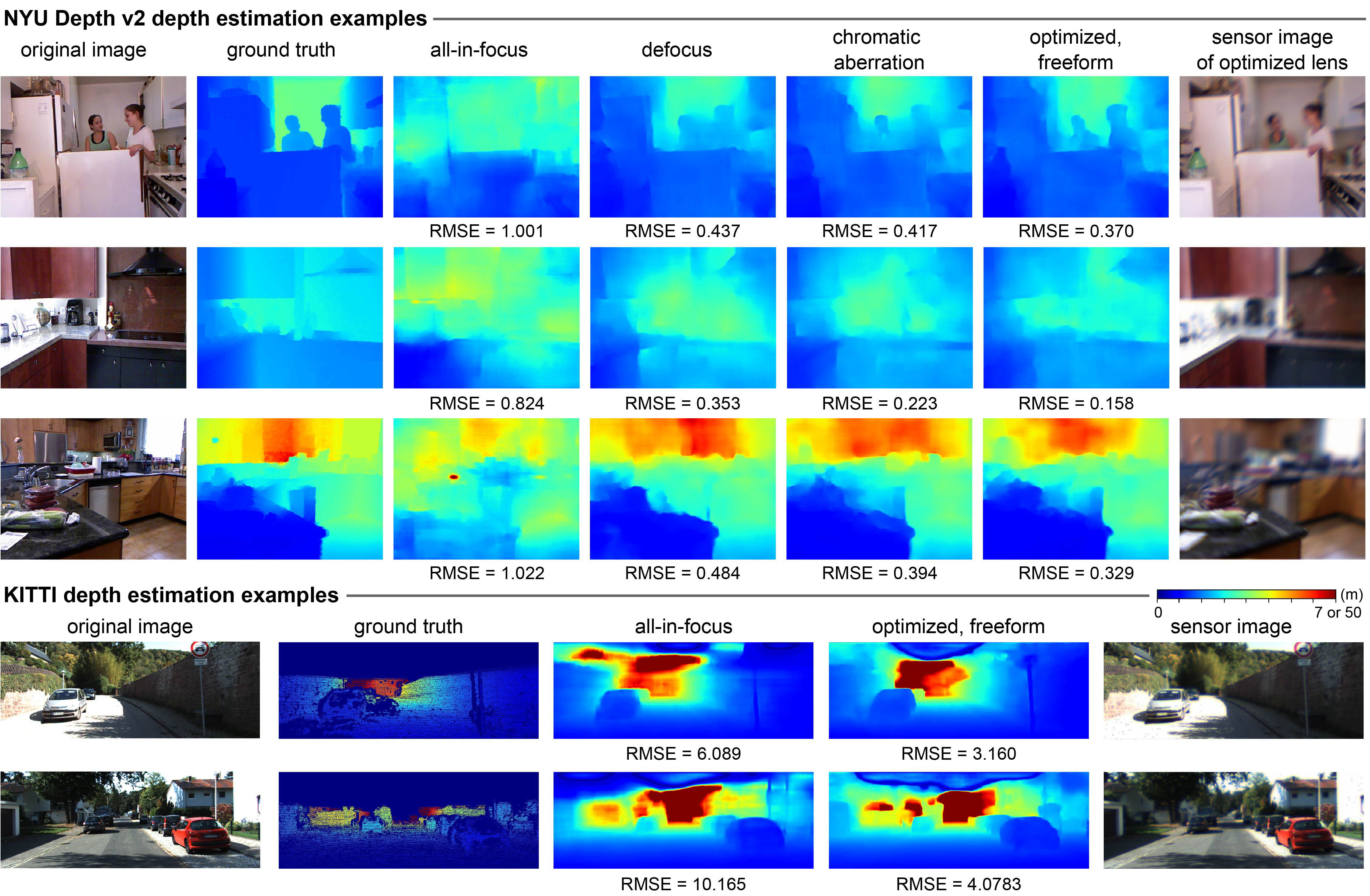
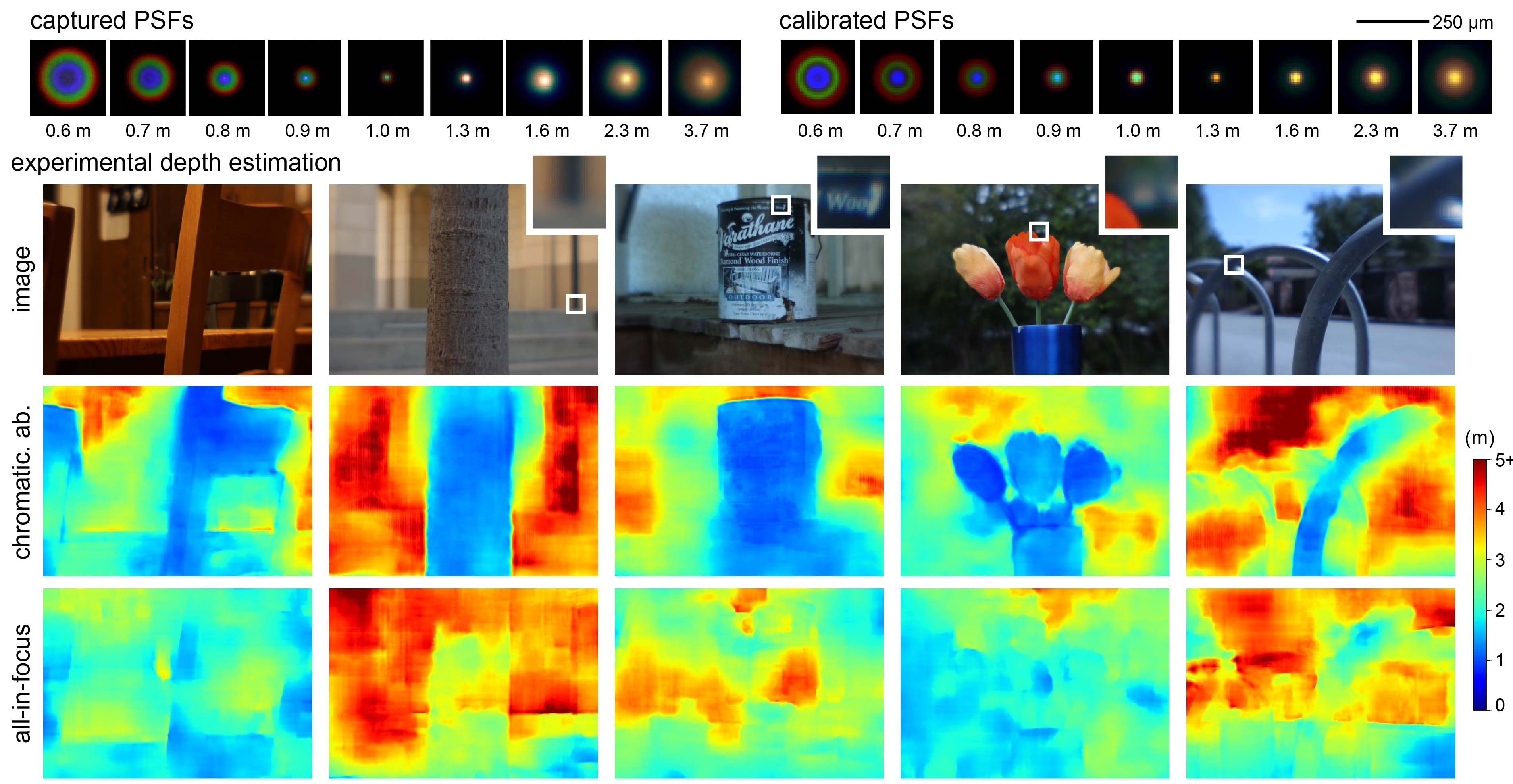
ABSTRACT
Depth estimation and 3D object detection are critical for scene understanding but remain challenging to perform with a single image due to the loss of 3D information during image capture. Recent models using deep neural networks have improved monocular depth estimation performance, but there is still difficulty in predicting absolute depth and generalizing outside a standard dataset. Here we introduce the paradigm of deep optics, i.e. end-to-end design of optics and image processing, to the monocular depth estimation problem, using coded defocus blur as an additional depth cue to be decoded by a neural network. We evaluate several optical coding strategies along with an end-to-end optimization scheme for depth estimation on three datasets, including NYU Depth v2 and KITTI. We find an optimized freeform lens design yields the best results, but chromatic aberration from a singlet lens offers significantly improved performance as well. We build a physical prototype and validate that chromatic aberrations improve depth estimation on real-world results. In addition, we train object detection networks on the KITTI dataset and show that the lens optimized for depth estimation also results in improved 3D object detection performance.