|
| From a parametric head model, we optimize its geometry and texture to fit a text prompt. This generated avatar can easily be articulated. |
ABSTRACT
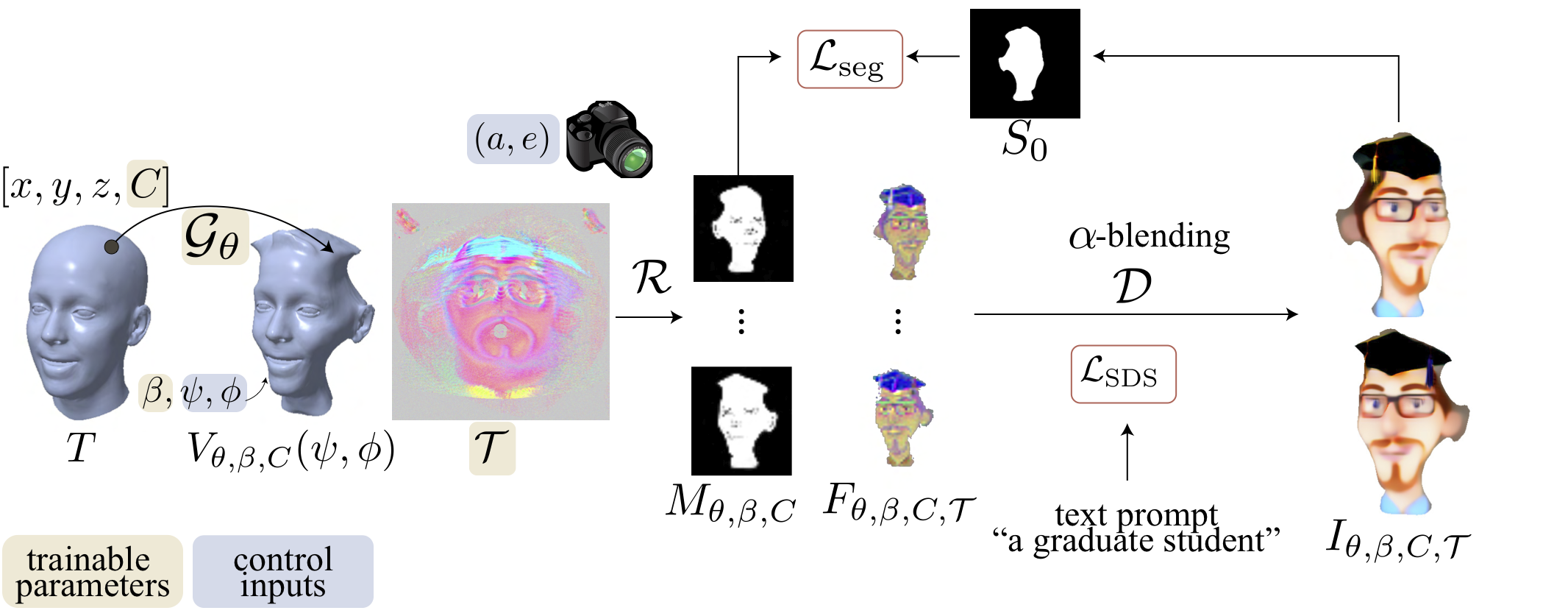
The ability to generate diverse 3D articulated head avatars is vital to a plethora of applications, including augmented reality, cinematography, and education. Recent work on text-guided 3D object generation has shown great promise in addressing these needs. These methods directly leverage pre-trained 2D text-to-image diffusion models to generate 3D-multi-view-consistent radiance fields of generic objects. However, due to the lack of geometry and texture priors, these methods have limited control over the generated 3D objects, making it difficult to operate inside a specific domain, e.g., human heads. In this work, we develop a new approach to text-guided 3D head avatar generation to address this limitation. Our framework directly operates on the geometry and texture of an articulable 3D morphable model (3DMM) of a head, and introduces novel optimization procedures to update the geometry and texture while keeping the 2D and 3D facial features aligned. The result is a 3D head avatar that is consistent with the text description and can be readily articulated using the deformation model of the 3DMM. We show that our diffusion-based articulated head avatars outperform state-of-the-art approaches for this task. The latter are typically based on CLIP, which is known to provide limited diversity of generation and accuracy for 3D object generation.