ABSTRACT
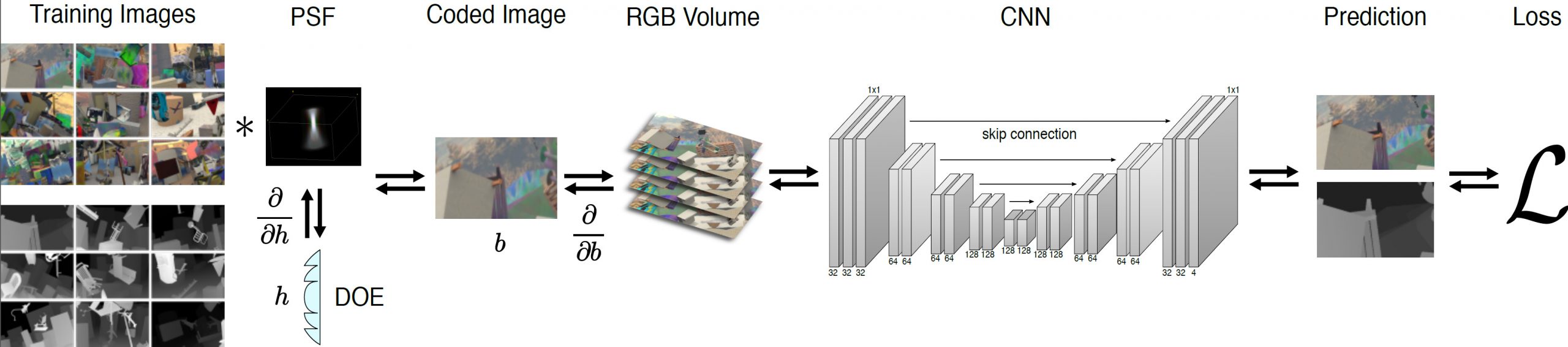
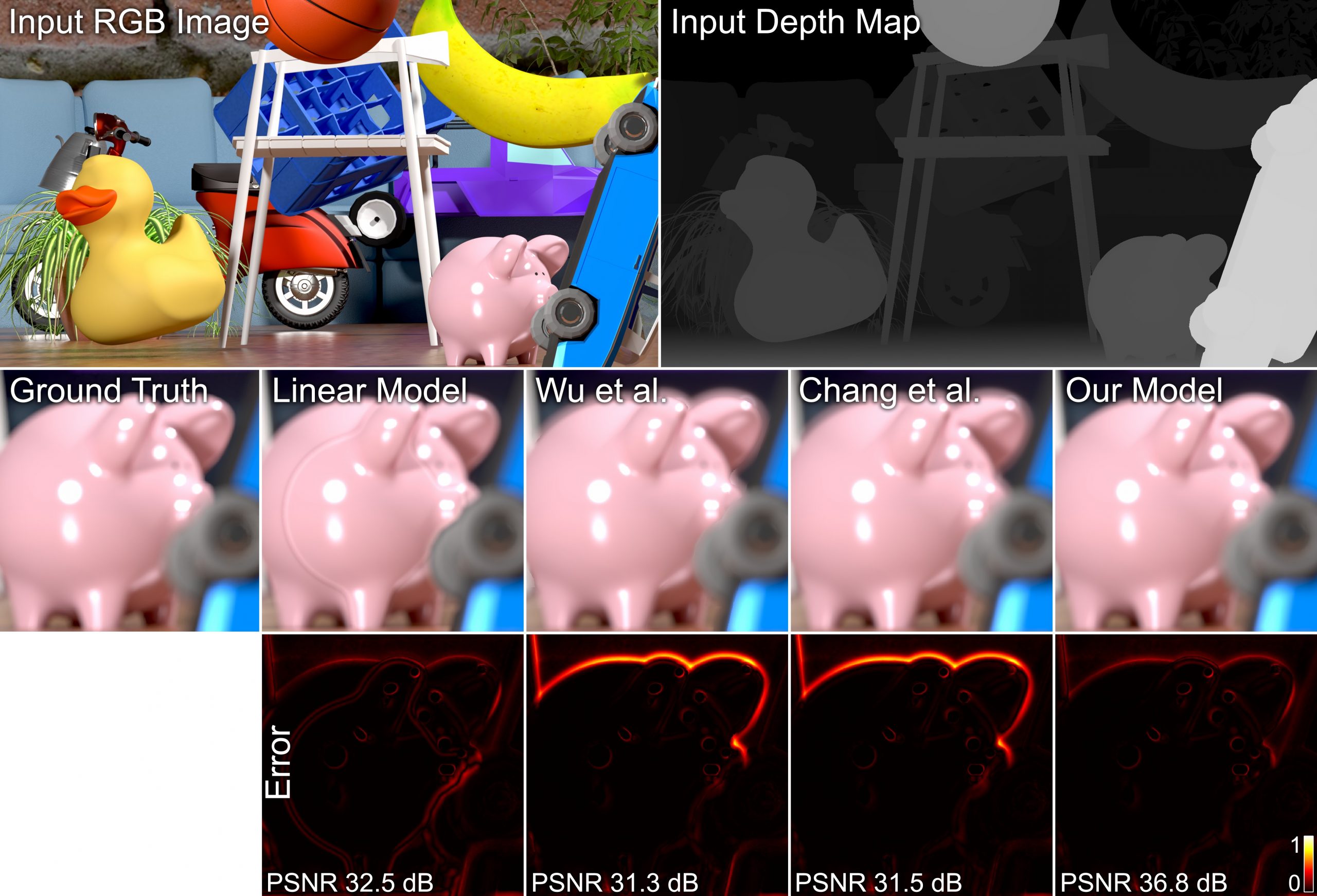
Monocular depth estimation remains a challenging problem, despite significant advances in neural network architectures that leverage pictorial depth cues alone. Inspired by depth from defocus and emerging point spread function engineering approaches that optimize programmable optics end-to-end with depth estimation networks, we propose a new and improved framework for depth estimation from a single RGB image using a learned phase-coded aperture. Our optimized aperture design uses rotational symmetry constraints for computational efficiency, and we jointly train the optics and the network using an occlusion-aware image formation model that provides more accurate defocus blur at depth discontinuities than previous techniques do. Using this framework and a custom prototype camera, we demonstrate state-of-the art image and depth estimation quality among end-to-end optimized computational cameras in simulation and experiment.